Revisiting Generative AI and Photography
"Machines will be capable, within twenty years, of doing any work a man can do.”
— Herbert A. Simon (1965)
In July 2023, I attended in an AI research forum. An Amazon researcher introduced to us several AI projects currently undertaken at Amazon. During the event, we had lunch together. When she learned that I was also a photographer, she bluntly said to me: "Midjourney ended photography!"
Although I cannot agree with this statement, her words present the view of many professionals engaged in the cutting-edge research on generative AI.
In this article, from the perspectives of both as an AI scientist and as a professional photographer, I try to thoroughly explore the profound impact that generative AI is having on traditional photography; and how we, as photographers, should face it to this challenge.

“On the mountain”. Generated on Midjourney, by Yan Zhang.
Contents
Early Prediction about AI
The Research and Development of Generative AI
Midjourney vs Stable Diffusion
The Photographers’ Confusion
Ownership and “Content Authenticity”
Outlook – Photography Will Become More Diversified
Early Prediction about AI
During the summer workshop at the Dartmouth College in 1956, a group of young American computer scienDsts led by John McCarthy (1927-2011) first proposed the term Artificial Intelligence (AI). This summer workshop was later recognized as a landmark historical event that established the field of artificial intelligence.
We know that in 1951, the world's first general-purpose electronic computer UNIVAC I was born in the United States; in 1953, IBM launched the world's first IBM 650 magnetic drum data-processing computer that could perform large-scale computations. It can be said that AI and computer science have almost completely synchronous development histories.

“A programmer 1950s”. Generated on Midjourney, by Yan Zhang.
Turing Test
When talking about AI, people usually point to robots, and those specific hardware or software systems that can perform near-human activities physically, cognitively, or both.
So, what is artificial intelligence in a fundamental sense? In 1950, the British mathematician Alan Turing (1912-1954) published the famous paper "Computing machines and intelligence" in the philosophy journal Mind. In this paper, Turing proposed an imitation game, which became known as the "Turing test," to demonstrate how machines could exhibit intelligent behaviour comparable to humans.

Turning test. Generated on Stable Diffusion, by Yan Zhang.
Let’s first explain what the Turing test is.
There are three subjects in the Turing test: a person, a computer, and a (human) interrogator. We assume that the computer is equipped with a program that can answer any question sent by the interrogator, and that neither the person nor the computer is visible to the interrogator. We can imagine that the person and the computer are in two separate rooms, and the interrogator is outside the two rooms, so the interrogator does not know which room has the person and which room has the computer.
The interrogator's job is to ask them any questions and then use their answers to determine which of the two is a person and which is a computer.
The questions posed by the interrogator and the answers received must be transmitted in an impersonal manner, such as being entered on a keyboard and displayed on monitors in two rooms through a connection. At the same time, we assume that the interrogator has no information about either party beyond that obtained in the Q&A.
During the test, the person must answer questions truthfully and try to convince the interrogator that he is indeed human; but the computer is programmed to "lie" in an attempt to convince the interrogator that it is human.
If, in a series of such tests, the interrogator is unable to identify the real human subject in any consistent way, the computer is deemed to have passed this test.
The Computer Program That Passes the Turing Test
The "Turing test" has always been regarded as the most fundamental interpretation of machine intelligence, that is, artificial intelligence: when a computer has the ability to make it impossible for humans to distinguish the difference between it and humans (cognitively), we say this computer has the same intelligence as humans.
In the 70 years since the Turing Test was proposed, AI researchers have been trying to design various computer programs that can pass the Turing Test. It wasn't until 2014 that the first recognized such program was actually developed.
On June 7, 2014, in the Turing Test Competition hosted by the University of Reading in the UK, a computer program called "Eugene Goostman" passed the Turing Test. In this competition, the program Goostman convinced 33% of the interrogators participating in the udging process to believe its self-description: a 13-year-old boy from Ukraine.

"In the 2014 Turing Test Competition, the program "Eugene Goostman" passed the Turing test: 33% of the interrogators believed that it was a 13-year-old boy from Ukraine." Generated on Midjourney, by Yan Zhang.
Here we explain why this 33% ratio is important. In his original paper "Computing machinery and intelligence", Turing also gave a famous prediction: that by the year 2000, computer programs will be advanced enough that the average interrogators will not exceed 70% chance of correctly guessing whether they were talking to a human or a machine.
Here, the organizers of the competition regard Turing's prediction as a criterion for a program to pass the Turing test, and interpret "no more than 70% chance" as requiring more than 30% of the interrogators to be "fooled" by the program.
Herbert A. Simon’s Prediction
From the late 1950s to the late 1960s, it was the first 10 years of AI's vigorous development. Scientists were full of confidence in AI. AI research based on formal logics led by John McCarthy has made important progress. The "Advice Taker" program he developed became the first common-sense reasoning system. In addition, the "General Problem Solver (GPS)" developed by the Carnegie Mellon University research group led by Herbert Simon (1916 - 2001) is a more widely used intelligent reasoning system.
These early AI research results greatly inspired most AI and computer scientists at the time. In 1965, Herbert Simon made a new AI prediction that was bolder and more specific than Turing's prediction in 1950:
"Machines will be capable, within twenty years, of doing any work a man can do."
Although the AI development entered its long winter period from the mid-1970s, and Herbert Simon's unfulfilled prediction has been questioned, however, this prediction has a clear expression of the belief of most AI scientists: eventually machines will be able to do anything humans can do!

“An AI symposium in 1985. Researchers were having a heated debate on how AI should be developed.” Generated on Midjourney, by Yan Zhang.
Mini AI knowledge: John McCarthy (1927-2011) is known as one of the founders of AI, a former professor at Stanford University and a Turing Award winner. He has devoted his life to advocating formal logics based research methods in AI. In more than 20 years after 1980, the knowledge representation and reasoning he led became the mainstream of basic AI research, and some of the most important AI reasoning problems were able to obtain major results during this period.
Herbert A. Simon (1916 - 2001) is the only scientist who received both the Turing Award and the Nobel Prize (Economics), and is a former professor at Carnegie Mellon University. In the field of AI and computer science, in addition to his contributions to GPS, Simon also collaborated with Allen Newell (1927-1992, one of the collaborators of GPS and a winner of the Turing Award) to propose a theory that uses production rules to model human problem-solving behavior.
The Research and Development of Generative AI Models
Reasoning and learning are the two most important features of human intelligence. In AI research, it always revolves around these two themes. After entering the 21st century, AI has gradually emerged from its long winter, and machine learning research has begun to make new and critical breakthroughs.
Deep Learning and ImageNet
Deep learning based on neural networks is one of many machine learning methods. Many of its key concepts and technologies were proposed and developed in the 1990s.
But deep learning really began to show its superiority over other machine learning methods in the first decade of this century. In 2007, Fei-Fei Li, an assistant professor at Princeton University, began to build the ImageNet dataset based on Fellbaum's WordNet with the support of Christiane Fellbaum, who was also a professor at Princeton University. In the following years, ImageNet collected 14 million classified and annotated images, becoming the most used training dataset for computer vision research at that time.
It is worth mentioning that at that time, machine learning research was focused on models and algorithms, and the training datasets used by researchers were relatively small. Li was the first researcher to focus on establishing extremely large datasets.
In 2012, the AlexNet model based on deep convolutional neural network (Deep CNN) stood out in the large-scale ImageNet image recognition competition, defeating other machine learning algorithms in image recognition with significant advantages. Since then, deep learning based on neural networks has become the mainstream of machine learning research and has continued to yield breakthrough results.
Generative Adversarial Networks (GANs)
In 2014, Canadian researcher Ian Goodfellow and his collaborators proposed a new neural network learning architecture, namely the generative adversarial network GAN, thus opening up a new research direction in generative AI. We can understand the basic principles of the GAN model from the following figure.
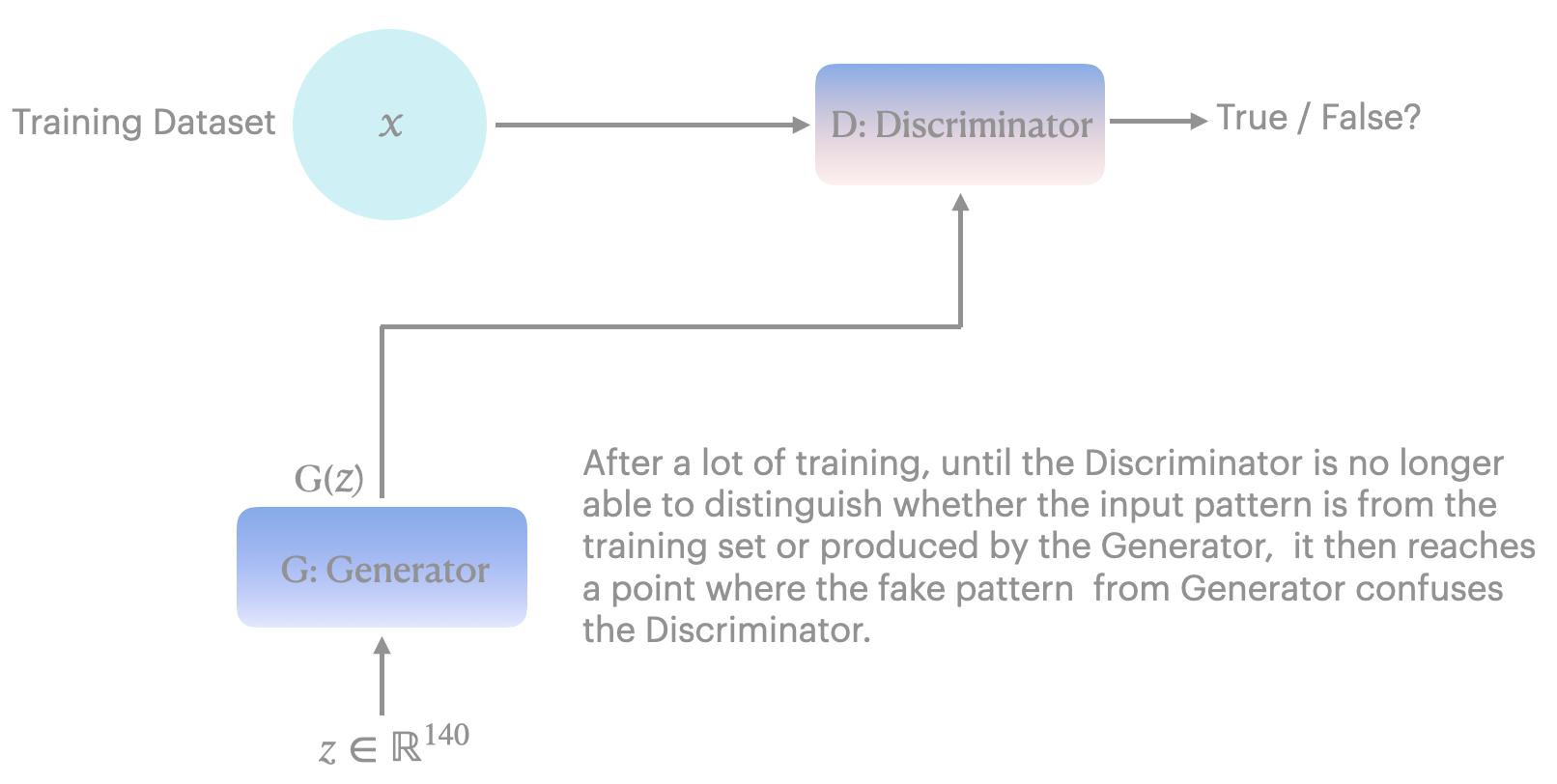
Figure 1. The general architecture of GAN.
Suppose we want to train an AI (GAN) model that can automatically generate human face panerns. First, we need to prepare enough (specific size) real human face photos as a training dataset, which is x in Figure 1. Secondly, we need to design two neural networks, called D and G - standing for discriminator and generator, respectively. Networks D and G compete in a zero-sum game mode: on the one hand, D continuously receives real face pictures from the training dataset and is told that these are human faces; on the other hand, network G generates a pattern, sends it to D and let it determine whether it is a human face pattern. Initially, G will only randomly generate irregular patterns. After D receives the face photo information from x, it is easy to recognise that the pattern generated by G is not a human face.
However, since both networks will continuously adjust their training parameters based on the evaluation results of each training cycle, the panerns produced by the generator are gradually getting close to human faces. This training process is repeated iteratively, and the pattern generated by the generator will continuously approach the real face pattern, until the discriminator can no longer tell whether the panern generated by G is a real face pattern input from x or a pattern generated from G.
Theoretically, in such a mutually competitive training method, G can eventually generate panerns that are not essentially different from any training dataset panerns.
However, in practice, it is still quite difficult to use GAN methods to generate realistic and very complex panerns. The most successful one is probably to generate realistic human face patterns: https://thispersondoesnotexist.com.
The main limitations of the GAN method are simply two aspects: First, the instability of training, which leads to model collapse and output low-quality pictures; second, because pictures are generated based on discrete pixel space, which may also easily lead to distortion or low-quality pictures.
Nevertheless, the GAN method has quickly become the mainstream of generative AI research since it was proposed. Researchers have jointly studied many different types of GAN models and key technologies related to them. Many of these results have also provided important support for the research on diffusion models.

Figure 2. Generated fractal images. Generated by Fractal_GAN model developed by the author.

Figure 3. Generated mountain images. Generated by Mountain_GAN model developed by the author.
Diffusion Models - A New Approach for Generative AI
The diffusion model is a new generative AI method proposed in 2015. Its intuitive idea can be understood through the following simple physical phenomenon.

Figure 4. An intuitive explanation of the diffusion model.
Suppose we drip a drop of blue ink into a glass of water (as shown in the lei picture above). Over time, the drop of ink will slowly spread, and finally dye the entire glass of water blue (as shown in the right picture above). This process is called forward diffusion. Now let's look at this diffusion process in reverse: if we know the diffusion trajectory of a drop of ink in clear water, then through reverse derivation, we can know the position and shape of the drop of ink in the clear water at the initial time. This process is called reverse diffusion.
Returning to the diffusion model, a clear image is equivalent to the initial drop of blue ink in the glass in our example above. The forward diffusion process of ink is equivalent to the process of continuously adding noises to the image, making the image slowly filled with noises. The reverse diffusion process of ink, on the other hand, is equivalent to the process of gradually removing noise from an image full of noises and restoring it to a clear image.
Through extensive learning and training, the diffusion model can finally obtain the distribution of noises in an image during the process of gradually adding noise, thus having the reverse diffusion process to remove noises and restore the original image. The general process is shown in the figure below.

Figure 5. Two diffusion processes in diffusion models.

The DeepMountain v1.1.4.2 model – that was developed and trained by the author based on the diffusion model architecture, can generate 512X512 high-quality mountain pictures, to the extent of photorealistic. Under the same prompts, the mountain imagines generated by DeepMountain v1.1.4.2 are richer than those generated by Midjourney v5.0 and SD v1.5.
Mini AI knowledge: Herbert Simon's prediction about AI made in 1965 did not come true. In the 50 years since then, people no longer seem to have expectations for Herbert Simon’s AI prediction. However, starting in 2016, this all began to change . . .
AlphaGo Zero: AlphaGo is a Go-playing computer program developed by DeepMind, a company located in London, England (later acquired by Google as a subsidiary). Unlike traditional AI chess-playing programs, AlphaGo's search algorithm is implemented through deep neural network training. In March 2016, AlphaGo defeated Korean 9-dan professional player Lee Sedol with a score of 4:1, and Lee became the only human Go player to have defeated the AlphaGo program.
In 2017, DeepMind launched a new version of AlphaGo called AlphaGo Zero. Compared with AlppaGo, this new version has made a significant leap: this intelligent program does not have any existing human knowledge about Go, that is, zero knowledge. All its subsequent knowledge about Go comes from self-learning - playing games with itself. It played 4,900,000 games against itself in three days. After 40 days of knowledge accumulation, AlphaGo Zero's Go level surpassed all older versions of AlphaGo programs.
On May 27, 2017, AlphaGo Zero competed with Ke Jie, the Chinese professional Go player ranked number one in the world at the time, and defeated Ke Jie 3:0.
At this point, AlphaGo Zero’s Go ability will never be surpassed by humans.
Midjourney vs Stable Diffusion
2023 will be definitely a year wrinen in the history of AI.
In early 2023, ChatGPT, a large language model (LLM) launched by OpenAI, reached 100 million users in just two months. By mid 2023, the applications of ChatGPT and its successor GPT-4 have significantly expanded from initial Question Answering, document editing and creation, to a wider range of finance, health care, education, soiware development, etc.
At the same time, research on the diffusion model based image generation represented by Midjourney, Stable Diffusion, and DALL.E 2 have also achieved major breakthroughs. The main function of these models is to generate imagines of various styles from prompts. The most amazing of them is that the Midjourney and Stable Diffusion models can generate realistic images similar to photography.
Images Generated by Midjourney
Generally speaking, Midjourney can use relatively simple and direct prompts to generate high quality and photorealistic images. Here we demonstrate several various images generated by v5.0 and v6.0 versions.

“Everest Base camp”. Generated on Midjourney, by Yan Zhang.

“A young woman portrait”. Generated on Midjourney, by Yan Zhang.

“Mysterious forest”. Generated on Midjourney, by Yan Zhang.

“Dream seascape”. Generated on Midjourney, by Yan Zhang.
From the pictures above, we can see that Midjourney can produce nearly perfect "photographs". Midjourney is also good at generating non-photographic artworks, and can generate such artworks with even specific artist styles, as shown in the following.

“Picasson’s women”. Generated on Midjourney, by Yan Zhang.
The power of Midjourney with image generation has been widely recognised. However, since it is a fully closed system, Midjourney's model structure and training methods are unknown to the public, and users have to pay fees for using it through the Discord platform.
Stable Diffusion Model Structure
Stable Diffusion is an image generation diffusion model launched by Stability AI in July 2022. Unlike Midjourney, Stable Diffusion is a completely open system, so we can understand all examine all technical details of this model from the structure to the training process.

Figure 6. The main model structure of Stable Diffusion.
After we know the basic idea of the diffusion model (see Figure 4 and Figure 5), it is not difficult to understand the structure of the Stable Diffusion main model in Figure 6. The training image x is compressed into a latent vector z by the encoder, and the process of forward diffusion begins. During this process, noises are gradually added to the latent vector, and finally transformed into a noise latent vector zT; then the reverse diffusion begins. process. At this time, the additional "text/image" condition is converted into the representation of a latent vector through a transformer and implanted into the reverse diffusion process. In this reverse diffusion process, the neural network U-Net uses a specific algorithm to gradually remove noises, restore it to a latent vector z, and finally generates a new image x^ through the decoder.
It should be noted that aier the model completes training, we only need to use the reverse diffusion process as an inference engine to generate images. At this time, the input text/image is converted into a latent vector through the transformer, and reverse diffusion through U-Net begins to generate a new image.
The Stable Diffusion model in Figure 6 can also be roughly divided into three major components: the leftmost red module VAE, the middle green module U-Net, and the rightmost Conditioning transformer. Such a structural diagram will facilitate the description of the Stable Diffusion extension we will discuss later.

Figure 7. The three modules of Stable Diffusion correspond to the main structure in Figure 6. VAE (Variational AutoEncoder) compresses and restores images; U-Net neural network is used for the reverse diffusion process, which we also call inference; Conditioning transformer is an encoder used to convert text and image conditions, attached to the reverse diffusion process.
Stability AI uses 5 billion (image, text) pairs collected by LAION as the training dataset, where each image size is 512X512. The compuDng resources used for model training are 256 Nvidia A100 GPU processors on Amazon Web Services (AWS) (each A100 GPU has a capacity of 80 GB); the iniDal model training took 150,000 GPU hours and cost USD $600,000.
Images Generated by Stable Diffusion
Generally speaking, under the same prompt words, the quality of the pictures generated by Stable Diffusion is not as good as Midjourney. For example, using the same prompts of the "Mysterious forest " picture generated by Midjourney above, the picture generated by SD v1.5 is as follows:

"Mysterious forests". Generated on Stable Diffusion (use the same prompts as the same titled image shown above), by Yan Zhang.
Obviously, the quality of the picture above is not as good as the one generated by Midjourney, both in terms of photographic aesthetics and image quality. However, it would be a mistake to think that Stable Diffusion is far inferior to Midjourney.
Because it is open source, Stable Diffusion provides people with unlimited possibilities for subsequent research and development in various ways. We will briefly outline the work in this area below.
Using a rich prompt structure and various extensions, Stable Diffusion can also generate realistic “photography works" comparable to Midjourney.

“Future city”. Generated on Stable Diffusion, by Yan Zhang.

“A young woman portrait”. Generated on Stable Diffusion, by Yan Zhang.

“Alaska Snow Mountain Night”. Generated on Stable Diffusion, by Yan Zhang.
Stable Diffusion Extensions
The open source of Stable Diffusion allows AI researchers to carefully study its structure and source code, so as to make various extensions to the model and enhance its functions and applications.
The expanded research and development of Stable Diffusion is basically focused on the UNet part (see Figure 7). There are two main aspects of the work: (1) Based on the original Stable Diffusion U-Net, with a small amount of specific dataset to train a personalized U-Net sub-model. In this way, when the sub-model is embedded in Stable Diffusion, it can generate images with personalized styles that users want. Dreambooth, LoRA, Hypernetworks, etc., all belong to this type of work.
(2) Enhance control over the image generation process of Stable Diffusion. Research in this area is to design and train a specific neural network control module so that in the process of image generation by Stable Diffusion, users can directly intervene according to their own requirements, such as changing the posture of the character, replacing the face or background, etc. ControlNet, ROOP, etc., are all control module extensions that belong to this category.
In addition, we can also revise the original U-Net structure of Stable Diffusion and use a specific training dataset to train part or all of the modified diffusion model. The underlying diffusion model trained in this way can be targeted at specific application domains, such as medicine, environmental science, etc.

Stable Diffusion sub-model example. The author of this article downloaded 7 photos of Tom Hanks from the Internet as shown in (a). Then use the extension Dreambooth to train these only 7 photos to generate an "AI-TomHanks" sub-model. Embedding this sub-model in Stable Diffusion can generate an AI version of the Tom Hanks picture, as shown in (b).
In addition to U-Net, we can also make more modifications and extensions to Stable Diffusion in the two parts of VAE and Conditioning transformer, which we will not go into details here.
Comparisons between Midjourney and Stable Diffusion
Here based on my own experience, I made the following comparison of the six main features of the two.

User friendliness: From a user’s perspective, I think Midjourney is easier to use than Stable Diffusion. It is easier for people to generate more satisfactory pictures on Midjourney. If you are a Stable Diffusion user, you will find that in order to generate a high-quality image, in addition to working on prompts, you also need to have a suitable sub-model (also called checkpoint), no matter whether you are using SD v1.5 or SD XL v1. 0, therefore, it is relatively difficult.
Flexibility: In the process of image generation, Midjourney and Stable Diffusion provide different ideas and methods to control and modify the final output image. However, I think Midjourney's method is more intuitive and practical, giving users more flexibility. Although Stable Diffusion also provides more complex and richer image editing capabilities, such as inpainting, outpainting, upscaling, etc., it is not very easy to use in practice for ordinary users.
Functionality diversity: Because of open source and scalability, the functions of Stable Diffusion have been conDnuously enhanced, which has also made Stable Diffusion increasingly popular in various application domains in business, education, medical and scientific research. However, just from the aspect of artistic picture generation, both Midjourney and Stable Diffusion can generate stunning artistic pictures (photography, painting, cartoon, 3D, sculpture, etc.).
Image quality: Both systems can generate high-quality artistic images of all types. However, as mentioned before, Midjourney is slightly bener than Stable Diffusion in terms of the aesthetics and quality of the generated images.
Extendibility/Free use: First of all, Midjourney is not free to use, and it is not open source. For users who want to use generative AI soiware for free and have some IT knowledge background, I strongly recommend installing Stable Diffusion on their own computers, so that you can enjoy to freely create anything you are interested.
Photographers oien ask me, which one should we choose, Midjourney or Stable Diffusion?
My suggestions are as follows: (a) If you are limited by technology and/or resources (for example: you don’t know how to install and use Stable Diffusion, your computer does not have a certain GPU capacity), then you can just choose Midjourney. Although it requires a subscription fee, after learning, you will definitely be able to create great AI art works, and you can also use it to help you enhance your photography post-process workflow.
(b) If you are only interested in generating AI artwork and processing photos, I also only recommend using Midjourney and do not consider Stable Diffusion at all.
(c) If you have a certain IT knowledge background and are interested in the technical details of generating a wide range of artistic images, especially if you want to generate some personalized images, then I strongly recommend Stable Diffusion, because it is currently the most comprehensive generative AI soiware for image generation.

“Mountain sunrise”. Generated on Midjourney, by Yan Zhang.

“Silent valley”. Generated on Stable Diffusion, by Yan Zhang.
Mini AI knowledge: AI Winter - refers to the period from 1974 to 2000, when AI research and development, mainly in the United States, was at a low ebb, and research funding and investment were significantly reduced. The main reason for the AI winter is that since the mid-1960s, a series of large-scale AI research projects have failed or failed to make substantial progress. This includes: the failure of machine translation and single-layer neural network research projects in the late 1960s; the failure of speech understanding research at Carnegie Mellon University in the mid-1970s; and the stagnation of the fifth-generation computer research and large-scale expert system development during 1980s -1990s.
The Photographers’ Confusion
2023 is the first year that generative AI has great impact on photography.
According to a poll conducted by IMAGO in May 2023, 67% of photographers said they would refuse to use any generative AI soiware to improve their photography postprocessing workflow.
Many photographers and artists believe that their work is being used to train AI models without their consent, thus infringing on their copyrights.
In April 2023, the well-known photography online gallery 1x.com announced that the website would not accept any images generated by AI.
However, these resistance to generative AI have not alleviated the anxiety of traditional photographers about this new technology. On the contrary, the rapid development of
generative AI technology has brought more confusion to photographers.
Game Changer - the Generative Fill in Photoshop
In May 2023, Adobe added some of Adobe Firefly's generative AI functions to Photoshop (Beta) for the first time, namely "Generative Fill", which is of profound significance to all Photoshop users and photographers.
If the 67% of photographers mentioned above still insist on resisting any form of generative AI in their photography process, it is equivalent to saying: "I use Photoshop, but I will never use the generative fill function in it." Does this sound a bit strange?
In fact, once Photoshop comes with its own generative AI function, most photographers will inevitably integrate this new function into their post-processing workflow (except for some special circumstances, which we will talk about later).

The Generative Fill function of Photoshop (v25.4) is very powerful and is similar to Midjouorney in its ability to understand prompts.
For photographers, they can refuse to use Midjourney, Stable Diffusion, or other generative AI software, but they cannot avoid using Photoshop. I’ve heard some photographers describe the boundaries of their use of generative AI this way:
- "I only use AI to denoise, remove dust from photos and enlarge the photo size",
- "I only use AI to remove annoying sunlight halos from photos",
- "I only use AI to simplify the distant background",
. . .
There are many such "boundaries". Personally, there is no problem with any of this. But the impact of generative AI on photography is far more complex than setting these “boundaries.” We must rethink the nature of photography; under the influence of the rapid development of AI technology, where will photography eventually go?
The Embarrassment of Traditional Photography Competitions
Two important events occurred in the field of international photography competitions in 2023.
In April 2023, a work by German photographer Boris Eldagsen won first place in the "Creativity" category in the Sony World Photography Awards 2023 competition. However, Eldagsen later announced that it was an image generated by OpenAI's AI software DALL-E 2 and was not a photo taken by him, thus rejecting the award.

The AI generated image "The Electrician" won first place in the creativity category at the Sony World Photography Awards 2023.
Afterwards, the organiser of the competition, Sony Photography Organisation, did not provide any explanation on the matter. But in the 2024 competition rules, Sony organisers have added relevant regulations to prohibit images containing AI generated elements from participating in the competition.
The second major event is: In November 2023, the organizers of the prestigious World Press Photo Contest announced new rules, allowing AI generated images to participate in the "Open Format" category in the competition. However, such new rules immediately caused an outcry among photojournalism photographers. In the end, the organisers, under pressure, withdrew the new rules and banned AI generated images from participating in the competition.
However, the debating about photography and AI has not stopped.


Discussions triggered by the rules for entering AI images in the World Press Photo Contest.
In addition to the two major events above, in 2023, most mainstream photography competition organisations also promptly added new rules to restrict the participation of photographs containing AI generated elements in the competition.

Sony World Photography Awards 2024 has added new rules to restrict the entry of AI generated images.

The International Landscape Photographer of the Year (ILP) 2023 has also added new rules to prohibit the entry of images with AI-generated elements.
However, these competition rules that restrict AI images are unconvincing. First of all, in various international photography competitions, except for a few professional categories such as journalism, geographic, nature, etc., most photography competitions do not impose any restrictions on post processing. In other words, for the entries, photographers can do whatever they want with the original photos according to their own aesthetics styles and skills, and there is no requirement for the "authenticity" of the works to reality.
For example, as you can see from the above screenshot, the last sentence of the new rules added in ILP 2023 says: “Of course, you could use a camera to capture a pond or rose bushes and composite them into the photo yourself – that’s okay because the content wasn’t generated by AI.”
To put it simply, these rules are equivalent to say: as long as it is not generated by AI, you can do whatever you want.
People may ask: Since the competition organisers have no requirements for the authenticity of the entries themselves, why are they so resistant to AI-generated content?
Secondly, and most importantly, how can the judges of these competitions know whether an entry is AI-generated, or whether it has AI-generated elements?
Since the organizers of these photography competitions will not require participants to provide the original RAW files of their entries, these new rules restricting AI images are actually not feasible.
On November 19, 2023, photographer Alex Armitage published an article on the fstoppers website and made the following comments on the rules of ILP2023:

Screenshot of photographer Alex Armitage’s article.
Armitage wrote: “However, like many contests, they don’t do raw image verification. The lack of any raw verification is quite standard among most contests. Thus, how would you actually know if AI was or was not used?”
In contrast to those organized by mainstream photography competitions, some regional photography competition organizations are completely open to generative AI. For example, the rules of the 2024 Brisbane Portrait Prize QPP just announced:

The QPP2024 competition is fully open to AI-generated images. The first rule states: “An original artwork, entirely completed and owned outright by you. QPP accepts entries that were completed in whole or in part by generative AI, subject to compliance with these terms.”
Mini AI knowledge:
Several platforms that support Stable Diffusion:
Online platform DreamStudio: This is a web app provided by Stability AI. For users who do not want to install the Stable Diffusion platform on their personal computers, they can directly run Stable Diffusion v1.6 and Stable Diffusion XL v1.0 online. It is intuitive and simple to use. However, its functionality is quite limited and cannot be compared with other local platforms.
Automatic1111: This is a Stable Diffusion platform based on a browser interface and can run under different operating systems. Therefore, whether you are using PC, Mac, or Linux station, you can run Stable Diffusion and Stable Diffusion XL locally by installing Automatic111. Full information on installing Automatic1111 can be found on the github website.
ComfyUI: This is a Stable Diffusion platform based on node processes. The interface is very different from Automatic1111. It can also run under different operating systems. The biggest advantage of ComfyUI is its high degree of computation optimization and user customizability. Whether running SD v1.5 or SD XL v1.0, ComfyUI is much faster than Automatic1111 (average 3-5 times according to testing). Again, full information on installing ComfyUI can be found on the github website. The only drawback is that it takes more time to learn and master.
Ownership and “Content Authenticity”
The Ownership of AI Artworks
Nowadays, it is common knowledge that artists have the copyright to their own artworks, and photographers are no exception. But the emergence of generative AI has shaken people's commonsense.
Currently, there are two opposing attitudes regarding whether AI-generated artworks should have copyright protection.
The reason for opposition is that the artistic pictures generated by AI are not obtained through human creative activities, and (U.S.) copyright law clearly stipulates that only human can have ownership of an artwork.
On September 5, 2023, the U.S. Copyright Office rejected artist Jason M. Allen's application for copyright registration of his AI generated work Theatre D'opera Spatial.

”Theatre D'opera Spatial”. Generated on Midjourney, by Jason M. Allen.
The Copyright Office concluded that using AI to create art is a "merely mechanical" process with "no place for novelty, invention or originality", and hence not worthy of copyright protection.
However, anyone who knows something about Midjourney would understand that the process of generating an image like Theatre D'opera Spatial is definitely a very creative task. It is said that Jason Allen spent more than 80 hours and used more than 600 promps to generate such a work on Midjourney.
Let’s briefly review the historical process of obtaining copyright protection for photographic works.
In the early 1880s, almost 70 years after the invention of the camera, there was ongoing controversy surrounding whether photographers' photos should be protected by copyright. The common view at the time was that photographs should not be protected by copyright because copyright should cover works that were part of a creative process, rather than a camera simply mechanically capturing whatever reality it was pointed at.
It was not until 1884 that the U.S. Supreme Court ruled in the case of photographer Napoleon Sarony, holding that his photo of Oscar Wilde should be protected by copyright. Since then, it has been widely accepted that photographers have the ownership of their own photographs (note: ordinary photos, such as snapshots, generally do not have copyright protection).

American photographer Napoleon Sarony's work "Oscar Wilde". In 1884, the U.S. Supreme Court ruled that Sarony owned the work.
However, some people believe that we should not directly use the copyright in photography as an example for the case of AI generated artworks. Their reason is that the generative AI model is developed after training on a huge amount of dataset that may include copyrighted artists' works. Therefore, the development process of the AI model itself may violate intellectual property infringement. So, these people believe that no artworks generated by AI models should be protected by copyright.
Regarding this argument, we may only wait for the legal professionals to provide more insights on this issue.

A black and white photograph or an AI generated image?
Entering 2024, as more and more AI artists emerge, and more generative AI is embedded into traditional photography software, there will be more and more demands from AI artists for copyright protection of AI art/photography works.
Under such an environment, I believe that relevant copyright laws will eventually be formulated, though this may take a long time.
The Issue of “Content Authenticity”
Another important issue related to generative AI is "content authenticity". With the increasingly widespread applications of generative AI, in practice, we need an effective method to make AI generated images or images containing AI generated elements recognisable or identifiable.
Only by finding and widely implementing this effective method will we be able to distinguish traditional photographs from images combined with AI generated technology, and thus formulate relevant rules according to our needs.
For example, with such recognizability, the above mentioned rule of the mainstream photography competition such as ILP2023: "Restrict the entry of AI generated pictures or pictures containing AI-generated elements" is truly feasible.
The Content Authenticity Initiative (CAI) currently led by Adobe provides an overall framework and standards for achieving this goal. Simply speaking, according to CAI's plan, any digital information, such as photos, videos, texts, sounds, etc., will have the essential metadata to indicate its source when it is initially generated. If this information is processed by any AI software, it will also be automatically recorded in metadata. In this way, no matter how this digital information spreads and changes, the metadata information related to it will always accompany it.
In October 2023, DALL-E.3 released by OpenAI took the lead in embedding “content authenticity" tags into the images it generates, taking the first step towards realizing CAI. However, there are still many difficulties from both technology and resource aspects to fully fulfil the goal of CAI, and it is unclear for us to predict when it will be truly popularized.

A creative photography work or an AI generated image?
Mini AI knowledge: AI ethics - This is an important aspect in the field of AI. With the rapid development and widespread application of generative AI technology, its importance is more prominent than ever.
Since AI will assist or replace some human activities and decisions, and the development of AI systems involves a large amount of data, if the AI system is used improperly or the data used in its development is incorrect (inaccurate), AI will potential dangers to human society.
AI ethics is a set of principles and guidelines about how we should develop and use AI. It usually includes five principles:
- Transparency
- Impartiality
- Accountability
-reliability
- security and privacy
These principles should be incorporated into the development and application of all AI systems.
Outlook - Photography Will Become More Diversified
Let us read Herbert Simon’s AI prediction once again:
"Machines will be capable, within twenty years, of doing any work a man can do."
As far as photography is concerned, we have reason to believe that this prediction is becoming a reality.
AI May Redefine the Essence of Photography
Generative AI makes us re-examine the essence of photography.
As a form of contemporary art, photography has long been beyond simply recording the reality of the world. If one of the essences of photography is to express emotions, awaken people’s consciousness, and thus inspire people, can AI also achieve this purpose?
Photographer Michael Brown is a professional journalist and documentary filmmaker, and has been a photographer for National Geographic magazine since 2004.
In April 2023, Brown used Midjourney to generate a series of AI pictures called "90 miles", which reproduced the Cubans' escape from Havana across the 90-mile strait to Florida in the form of realistic photographs.

“90 miles“. Generated on Midjourney, by Michael Brown.
Brown's "90 Miles" caused a big uproar in the international photojournalism community, and fierce debate ensued between supporters and opponents. However, in any case, (generative) AI has had a significant impact on photojournalism. How to use AI technology correctly will be a question that all photographers need to think about together.
As Brown himself said: “I share many of the common thoughts, concerns and opinions about AI, but there is no getting around that the technology is here. So how do we constrain it while using it to tell stories, especially stories impossible to photograph, that might generate empathy and awareness of important issues?”

"The bombing of London on September 7, 1940 (I)". Generated on Midjourney, by Yan Zhang.

"The bombing of London on September 7, 1940 (II)". Generated on Midjourney, by Yan Zhang.
AI Will Reshape the Art of Photography
In the current photography world, except to a few specific photography categories, such as photojournalism, geographic, nature, etc., where authenticity of the real world is key to reflect in the photographs, many other photography categories, such as black and white, landscape, architecture, creativity, etc., are mostly attributed to the generic type of artistic photography, for which the artistic post processing is a very important part of the overall creative process of this type of work.
As time goes by, people will become more open to accept AI generated art, and more and more photographers (especially new generation photographers) will use generative AI technology in their photography processes. This will objectively reshape the art of photography in the traditional sense, thus forming a large category of "AI art photography".

A still photography work or an AI generated image?
Before CAI (Content Authenticity initiative) is fully implemented in the entire photography industry (if there is such a day), since we cannot distinguish between traditional art photography and art photography involving AI components (without verifying the original RAW file), this will mostly result in a blurred boundary between traditional art photography and AI art photography.

A minimalist photograph or an AI generated image?
Traditional Photography and AI Photography Will Coexist
Although generative AI is having a huge impact on photography, it does not mean that photography will disappear. On the contrary, photography, as a form of artistic expression, will progress towards diversification.
Photography categories such as photojournalism, geographic and nature will continue to exist in their current form, because the human nature of pursuing the real world will not change. This type of photography will not be influenced by generative AI technology due to its special requirement for verifying original RAW files. We might as well call this type of photography as "pure photography".
All other photography categories that people are currently familiar with will inevitably be affected by AI technology. More traditional photography artists will actively or passively start to use AI technology. As a such, more photographic works will contain AI components in near future.
Faced with these challenges, I believe that most mainstream photography competitions will eventually add an "open format" category to accept AI generated works or works containing AI generated elements to participate in the competition. In this way, existing art photography will also be further divided into two classes: traditional art photography without AI components and "AI art photography", and the popularity of AI art photography is likely to increase rapidly.
As mentioned before, the boundaries between traditional art photography and emerging AI art photography are not very clear. In most cases, we can only trust what the photographer himself/herself declares whether his work does or does not contain AI components.
In terms of commercial photography, the impact of AI on the existing commercial photography market should not be underestimated. Media and industries that rely on commercial photography, such as fashion magazines, commercial advertisements, etc., are likely to turn to low-cost AI generated images, which will be a big challenge for professional photographers who make a living from commercial photography.
Whether we like it or not, the AI era has arrived. As photographers, we should embrace AI rather than reject it. Perhaps photographer Michael Brown’s choice will give us some inspiration: insist on being a photographer in the traditional sense, but also embrace AI to open up a new creative world.
Final Words
By the time I was writing this article, OpenAI released Sora on 15 February 2024. Sora is a text-to-video AI model that can create realistic and imaginative scenes from text instructions.
While Sora is still not available for public use, its potential impact to our world is unimaginable, and we will witness this very soon.

A frame grab from a video generated by Sora.
Above the Author
Zhang Yan is a professor of artificial intelligence at Western Sydney University in Australia and has been undertaking AI research for 30 years.
Zhang Yan is also a passionate natural landscape photographer, an outdoor and mountaineering enthusiast. He is dedicated to mountain photography, integrating extreme mountaineering into his landscape photography journey, and has captured unparalleled mountain sceneries around the world.
In 2022, Zhang Yan’s mountain photography work "Breaking Dawn" won the first place in the landscape category of Australian Geographic Nature Photographer of the Year Competition.